Groundingdino
GroudingDINO
1. 算法简介
1.1 论文相关背景
参考文章
Grounding DINO论文解读与代码调试_grounding dion 介绍-CSDN博客
(1) Close-Set & Open-Set
From Close-Set to Open-Set:introducing language to a closed-set detector for open-set concept generalization.

(2) Open-Set Detection Methods
How to Achieve Open-Set Detection:
Key 1: Using Large-Scale Semantic-Rich Data with Grounding
Key 2: Strong Architectures based on DlNO
Two Paths Open-Set:
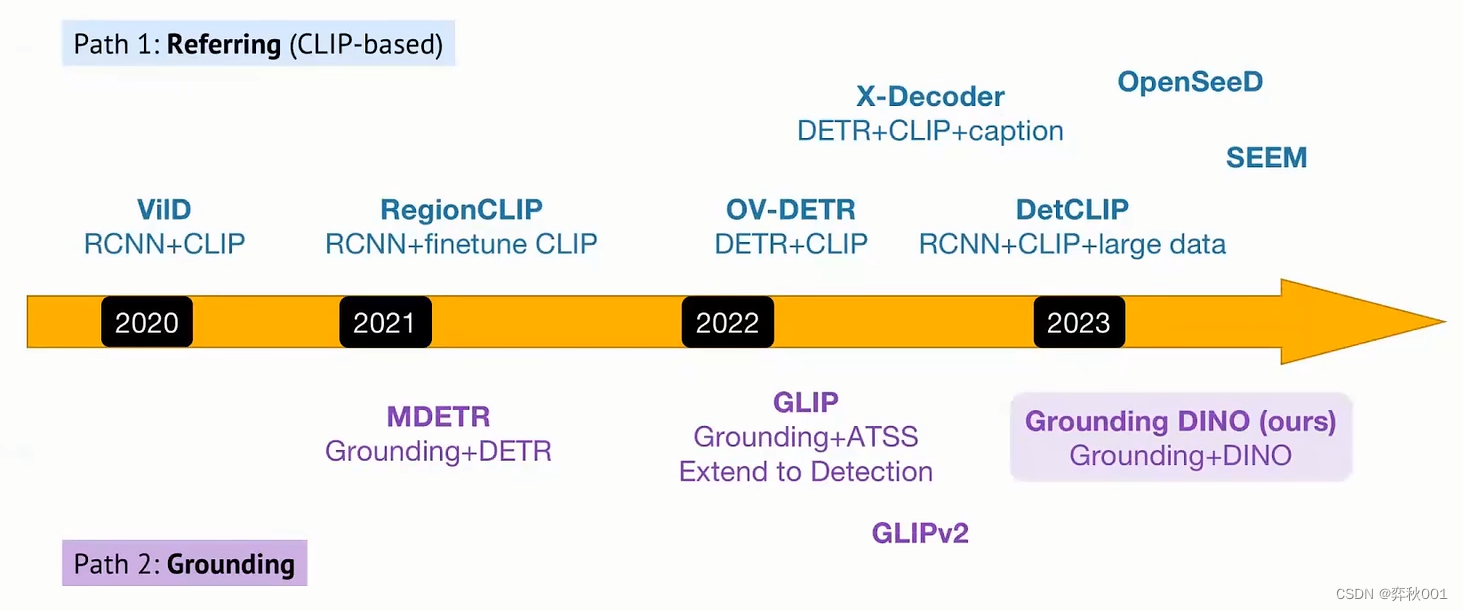
Referring & Grounding:
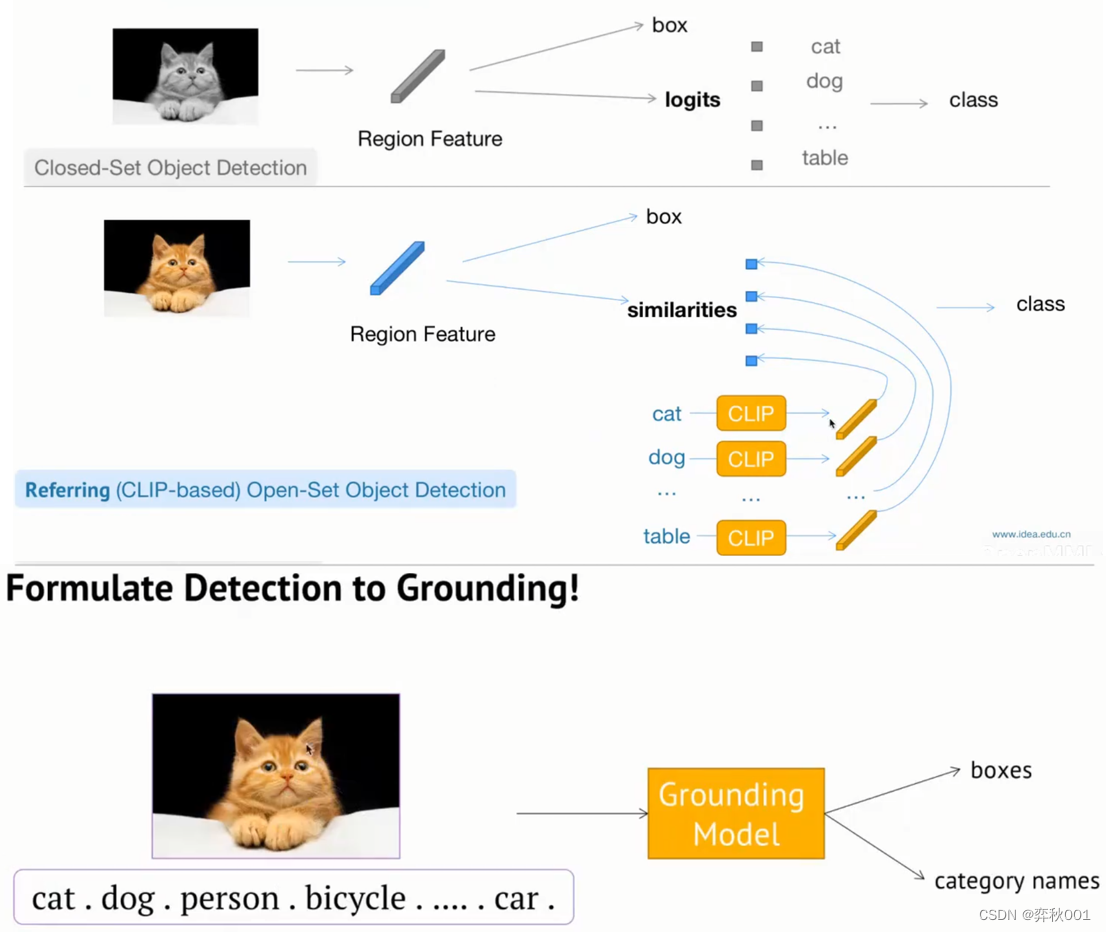
- 传统的卷积目标检测,是将类别输出投影到类别标签上,选出最大值作为当前box的类别。这里类别标签是预定好监督信号,输出logits不能超出这些类别。这是传统目标检测不能识别未见过的目标的根本原因
- referring的做法是,提取box的方法不变。从外部输入文本提取类别token, 然后这些类别经过clip模型转换成tensor向量,这些向量与视觉模型提取的类别logits tensor求相似度,最大的值就是当前box的类别,这种做法是开集检测方法之一。
- grounding意思是,给定图片和文本描述,预测文本中所提到物体的在图片中的位置, 如上图给定多个物品类别,cat、dog、person等,组成一句话。同时输入模型后,给出定位框box和类别值。


(3) Relevant Methods
a. CLIP(特征对其)
CLIP(Contrastive Language-Image Pre-Training)模型是一种多模态预训练神经网络,核心思想是使用大量图像和文本的配对数据进行预训练,以学习图像和文本之间的对齐关系。CLIP模型有两个模态,一个是文本模态,一个是视觉模态,包括两个主要部分,都是基于transformer架构:
- Text Encoder:用于将文本转换为低维向量表示-Embeding。
- Image Encoder:用于将图像转换为类似的向量表示-Embedding。
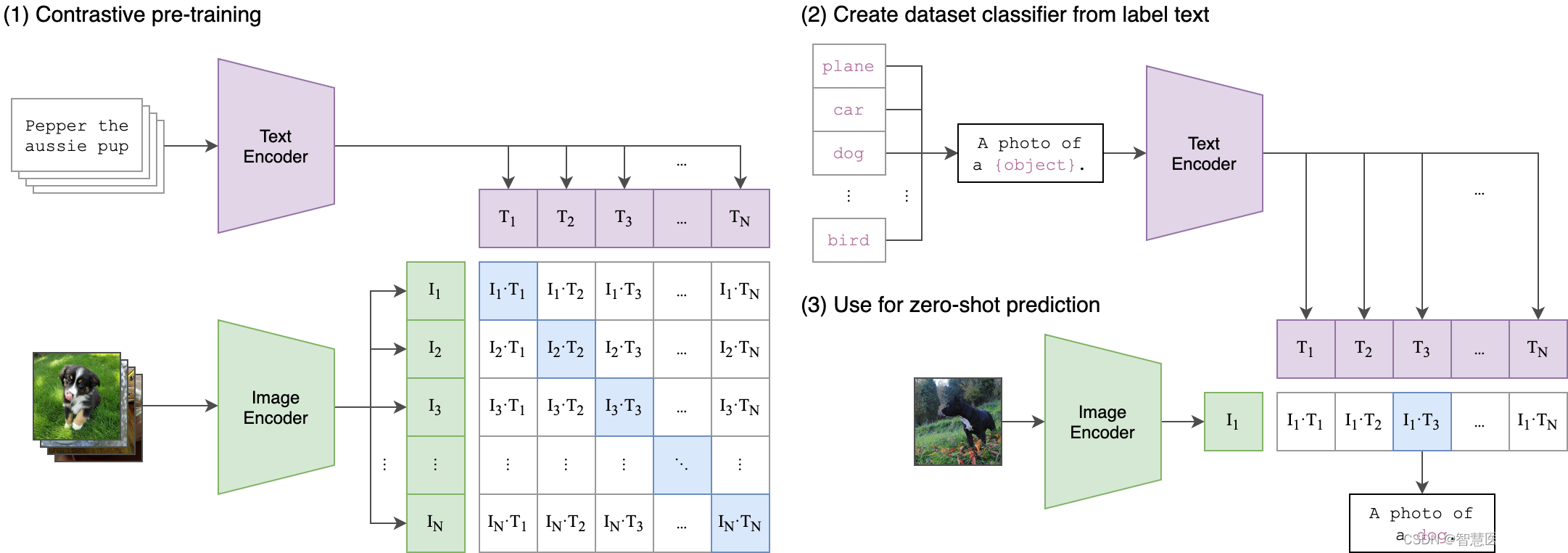
图像编码器有两种架构,一种是使用ResNet50 作为基础架构,并在此基础上根据ResNetD的改进和抗锯齿rect-2模糊池对原始版本进行了修改。同时,还将全局平均池化层替换为注意力池化机制。注意力池化机制通过一个单层的“transformer式”多头QKV注意力,其中查询query是基于图像的全局平均池表示。
第二个架构使用最近引入的Vision Transformer(ViT)进行实验。只进行了小修改,即 在transformer之前对 combined patch 和 position embeddings添加了额外的层归一化,并使用稍微不同的初始化方案。
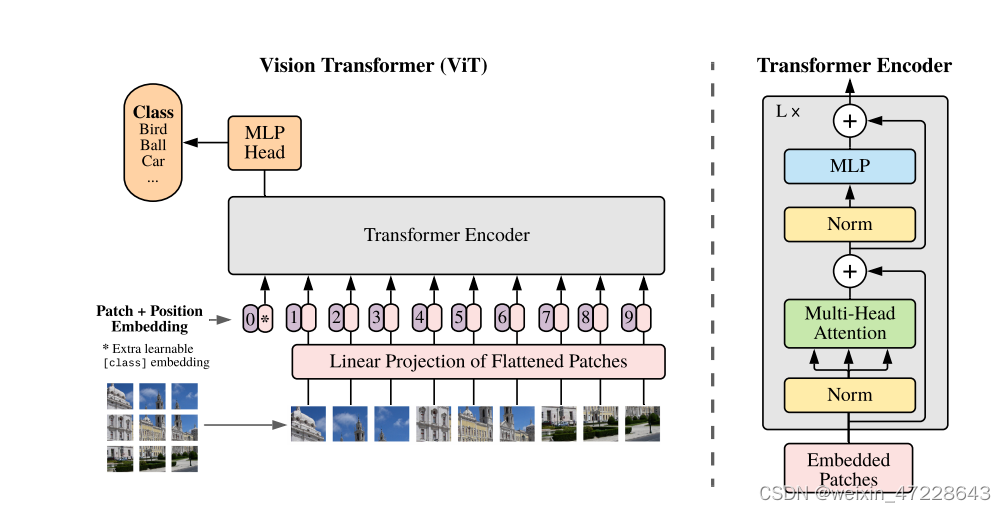
文本编辑器是Transformer架构,如下图所示,并在此基础上根据Radford模型进行了架构修改。作为基础尺寸,文章使用12层512宽的模型,有8个注意头。transformer执行对文本的小写字节对编码(BPE)的表示。 文本序列用[SOS]和[EOS]令牌括起来,[EOS]令牌上transformer最高层的激活函数(层归一化)被用作文本的特征表示,然后线性投影到多模态嵌入空间中。在文本编码器中使用了隐藏的自注意,以保留添加语言模型作为辅助目标的能力。
b. RCNN
R-CNN物体检测系统由三个模块构成:
产生类别无关的region proposal,这些推荐定义了一个候选检测区域的集合,大约2000个; 一个大型的卷积神经网络(AlexNet,5conv+2fc+1softmax总计约6000万的参数量,2013年),用于从每个区域抽取特定大小的特征向量; 一个指定类别的线性SVM分类器以及拟合边框回归。 
c. F-RCNN
Fast R-CNN相对于R-CNN的主要改进点:
共享卷积特征映射:
在R-CNN中,每个候选区域都需要单独通过卷积神经网络进行前向传播以提取特征,这导致了大量的计算冗余。 Fast R-CNN则首先在整个输入图像上进行一次卷积操作,产生一个全局共享的特征图。所有候选区域(RoIs, Regions of Interest)都在这个特征图上进行操作,极大地减少了计算量。
RoI池化层(RoI Pooling Layer):
引入了RoI Pooling层,用于处理不同尺寸和比例的候选区域。它将每个候选区域映射到一个固定尺寸的小区域上,确保特征可以统一输入到全连接层进行分类和位置回归。 这个层允许模型在不丢失重要信息的情况下对不同大小的目标进行标准化处理,简化了后续的分类和定位工作。
端到端训练:
R-CNN的训练过程涉及多个独立阶段,包括预训练CNN、训练SVM分类器和边框回归器。 Fast R-CNN整合了分类和定位回归的任务,构建了一个单一的多任务损失函数,使模型可以进行端到端(end-to-end)训练,简化了训练流程,提高了训练效率和准确性。
Faster R-CNN对Fast R-CNN所做的关键改进在于引入了一个新的组件——区域提议网络(Region Proposal Network, RPN):
Faster R-CNN直接在网络内部实现候选区域的生成,通过共享卷积特征图的方式,RPN可以在一张特征图上滑动窗口,并应用小型卷积网络预测每个位置的潜在目标边界框以及每个边界框是否包含对象的概率。 RPN可以同时生成多个不同尺度和比例的锚框(Anchor Boxes),并通过训练学习如何调整这些锚框以适应不同大小和形状的目标物体。 Faster R-CNN的主要贡献在于通过内建的RPN实现了候选区域提议的高效生成,并且通过共享特征、联合训练等策略整合成了一个更为流畅且高效的端到端目标检测框架,极大地提升了目标检测的速度和准确性。
d. DETR
DETR是 Facebook 团队于 2020 年提出的基于 Transformer 的端到端目标检测,没有非极大值抑制 NMS 后处理步骤、没有 anchor 等先验知识和约束,整个由网络实现端到端的目标检测实现,大大简化了目标检测的 pipeline。 它分为四个部分,首先是一个 CNN 的 backbone,Transformer 的 Encoder,Transformer 的 Decoder,最后的预测层 FFN。


f. Grounding

g. GLIP
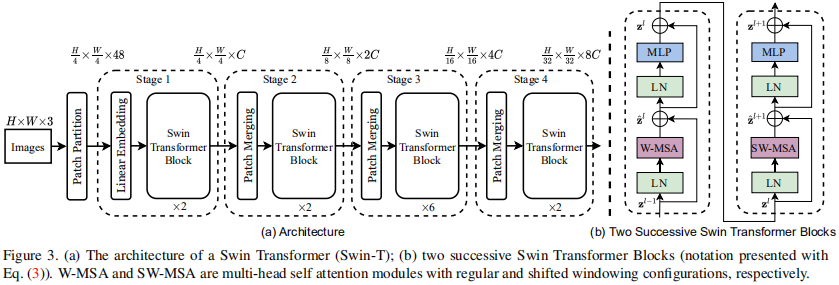
h. Swin Transformer
【深度学习】详解 Swin Transformer (SwinT)-CSDN博客
1.2 论文详细解读
1. Introduction
传统闭合集检测器通常具有三个重要模块,一个用于特征提取的主干、一个用于特性增强的Neck和一个用于区域细化(或边界框预测)的head。
图显示了特征融合可以分三个阶段进行:neck(阶段A)、查询query初始化(阶段B)和head(阶段C)。例如,GLIP[26]在neck(阶段A)模块中执行早期融合,OV-DETR[56]使用语言感知查询作为head模块(阶段B)输入。

核心是pipiline中更多的特征融合。像Faster RCNN这样的经典检测器的设计使得在大多数块中很难与语言信息交互。与经典检测器不同,基于Transformer的检测器DINO具有与语言块一致的结构。根据这一原则,我们在颈部、query初始化和head阶段设计了三种特征融合方法,更具体地说,我们通过堆叠自注意力、文本到图像的交叉注意力和图像到文本的交叉注意力作为颈部模块来设计特征增强器。然后,我们开发了一种语言引导的查询选择方法来初始化head的查询。我们还为头部阶段设计了一个具有图像和文本交叉注意力层的交叉模态解码器,以增强查询表示。
同时我们还考虑了另一个重要的场景,参考表达理解(REC),即用属性来描述对象。我们在所有三种配置上进行了实验,包括闭合集检测、开放集检测和引用referring对象检测,并取得了较好结果。
2. Related Work(略)
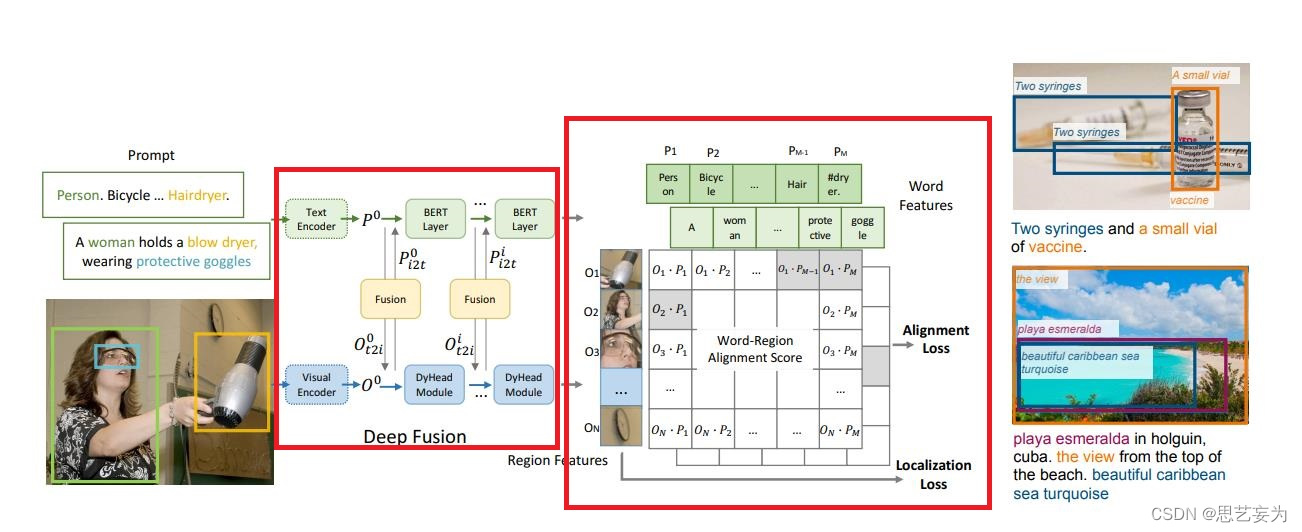
3. Grounding DINO
Grounding DINO为给定的(图像、文本)对输出多对对象框和名词短语。例如,如图3所示,该模型从输入图像中定位一个cat和一张table,并从输入文本中提取词cat和table作为相应的标签。目标检测和REC任务都可以与pipeline对齐。根据GLIP,我们将所有类别的名称拼接起来,作为对象检测任务的输入文本。REC要求每个文本输入都有一个边界框。我们使用得分最大的输出对象作为REC任务的输出。

Grounding DINO是一种双编码器-单解码器架构。它包含用于图像特征提取的图像主干、用于文本特征提取的文本主干,用于图像和文本特征融合的特征增强器(第3.1节),用于查询初始化的语言引导查询选择模块(第3.2节)和用于框细化的跨模态解码器(第3.3节)。总体框架如图3所示。
对于每个(图像、文本)对,我们首先分别使用图像主干和文本主干提取普通图像特征和普通文本特征。这两个普通特征被送到用于跨模态特征融合的特征增强器模块中。在获得跨模态文本和图像特征后,我们使用语言引导的查询选择模块从图像特征中选择跨模态查询。与大多数DETR类模型中的对象查询一样,这些跨模态查询将被送到跨模态解码器中,以从双模态特征中探测所需特征并更新它们自己。最后一个解码器层的输出查询将用于预测对象框并提取相应的短语。
3.1. Feature Extraction and Enhancer (特征提取和增强器) 给定(图像,文本)对,我们使用像Swin Transformer这样的图像主干提取多尺度图像特征,并使用像BERT这样的文本主干提取文本特征。继之前的类似DETR的检测器之后,从不同块的输出中提取多尺度特征。在提取普通的图像和文本特征后,我们将它们输入到特征增强器中进行跨模态特征融合。特征增强器包括多个特征增强层。我们在图3块2中说明了一个特征增强层。我们利用可变形的自注意力来增强图像特征,并利用普通的自注意力增强文本特征。受GLIP的启发,我们添加了一个图像到文本的交叉注意力和一个文本到图像的交叉注意力来进行特征融合。这些模块有助于调整不同模态的特征。
3.2. Language-Guided Query Selection (语言引导的查询选择器) Grounding DINO旨在从图像中检测输入文本指定的对象。为了有效地利用输入文本来指导对象检测,我们设计了一个语言引导的查询选择模块,以选择与输入文本更相关的特征作为解码器查询。我们在算法1中以PyTorch风格展示了查询选择过程。变量image_features和text_features分别表示图像和文本特征。num_query是解码器中的查询数,在我们的实现中设置为900。我们使用bs和ndim来表示伪代码中的batch size和特征维度feature dimension。num_img_tokens和num_text_tokens分别用于图像和文本tokens的数量。 语言引导查询选择模块输出num_query的多个索引。我们可以根据选择的索引提取特征来初始化查询。根据DINO,我们使用混合查询选择来初始化解码器查询。每个解码器查询分别包含两部分:内容部分和位置部分。我们将位置部分公式化为动态锚框,通过编码器输出对其进行初始化。另一部分,内容查询,被设置为在训练期间可以学习。

3.3. Cross-Modality Decoder (跨模态解码器) 我们开发了一个跨模态解码器来组合图像和文本模态特征,如图3块3所示。每个跨模态查询被送到自注意力层、用于组合图像特征的图像交叉注意力层、用来组合文本特征的文本交叉注意力层以及每个跨模态解码器层中的FFN层。与DINO解码器层相比,每个解码器层都有一个额外的文本交叉注意力层,因为我们需要将文本信息注入查询中,以实现更好的模态对齐。
3.4. Sub-Sentence Level Text Feature 在之前的工作中,我们探索了两种文本提示,分别命名为句子级表示和单词级表示,如图4所示。句子级表示将整个句子编码为一个特征。如果一些句子有在短语基础数据库中的多个短语,它会提取这些短语并丢弃其他单词。通过这种方式,它消除了单词之间的影响,同时丢失了句子中的细粒度信息。单词级表示允许用一个正向forward编码多个类别名称,但在类别之间引入了不必要的依赖性,尤其是当输入文本是多个类别名按任意顺序串联时。如图4(b)所示,一些不相关的单词在注意力过程中相互作用。为了避免不必要的单词交互,我们引入了注意力masks来阻断不相关类别名称之间的注意力,称为“子句”级表示。它消除了不同类别名称之间的影响,同时保留了每个单词的特征,以便进行细粒度的理解。
3.5. Loss Function 继之前类似DETR的工作之后,我们使用L1损失和GIOU损失进行边界框回归。我们遵循GLIP,使用预测对象和语言tokens之间的对比损失进行分类。具体来说,我们将每个查询与文本特征进行点乘,以预测每个文本token的logits,然后计算每个logit的focal损失。边界框回归和分类成本首先用于预测和gt之间的二分匹配。然后,我们计算gt和具有相同损耗分量的匹配预测之间的最终loss。根据类似DETR的模型,我们在每个解码器层和编码器输出之后添加辅助loss。
4. Experiments
在大规模数据集上进行了Zero-Shot Transfer of Grounding DINO,并进行了ablation studies,并说明了如何实现Transfer from DINO to Grounding DINO,因为从头开始训练Grounding DINO是expensive的,我们freeze the modules co-existing in DINO and Grounding DINO and fine-tune the other parameters only,结果是相似的
5. Conclusion
其他没什么好说的,主要是缺点:Grounding DINO cannot be used for segmentation tasks like GLIPv2.
附录
透露了详细的实施、数据、结果细节,并展示在Stable Diffusion方面的运用
主要是实施上的细节:
默认情况下,在DINO之后的模型中使用900个查询。我们将最大文本标记号设置为256。使用BERT作为我们的文本编码器,我们遵循BERT,使用BPE方案来标记文本。我们在特性增强器模块中使用了六个特性增强器层。交叉模态解码器也由6个解码器层组成。我们在图像交叉注意层中利用了可变形的注意。
匹配成本和最终损失均包括分类损失(或对比损失)、方框L1损失和GIOU损失。在DINO之后,我们在匈牙利语言匹配过程中,将分类成本、盒子L1框成本和GIOU成本的权重分别设置为2.0、5.0和2.0。在最终的损失计算中,相应的损失权重分别为1.0、5.0和2.0。
我们的双变压器微型模型在16个NvidiaV100gpu上进行训练,总批量大小为32个。我们提取了3个图像特征尺度,从8×到32×。它在DINO中被命名为“4尺度”,因为我们将32×的特征图降采样到64×作为一个额外的特征尺度。对于Swin变压器大模型,我们从骨干中提取4个图像特征尺度,从4×到32×。该模型在64个NvidiaA100gpu上进行训练,总批量大小为64个。

2. 本地部署
2.1 Linux
| [【计算机视觉 | 目标检测】Grounding DINO 深度学习环境的配置(含案例)_groundingdino-CSDN博客](https://blog.csdn.net/wzk4869/article/details/130582034) |
文本提示检测图像任意目标(Grounding DINO) 的使用以及全网最详细源码讲解_groundingdino-CSDN博客
2.2 Windows
git clone https://github.com/IDEA-Research/GroundingDINO.git
用pycharm/VScode/Jupyter Notebook打开GroundingDINO-main,运行其中的setup,或按照其进行安装相关包
下载: https://github.com/IDEA-Research/GroundingDINO/releases/download/v0.1.0-alpha/groundingdino_swint_ogc.pth
Jupyter Notebook随后可以打开test,修改其中的路径后运行
debug
a. huggingface连接问题1

诊断:常见的Transformer使用报错问题,原因是网络的无法稳定连接到 https://huggingface.co,方案一是使用代理(科学上网配置也可能出问题),方案二是使用镜像网站(https://hf-mirror.com/),方案三是离线调运包(https://huggingface.co/docs/transformers/installation#offline-mode),方案一是最简单的,方案三复杂
笔者采用方式三解决,参考HuggingFace 模型离线使用最佳方法!_huggingface离线模式-CSDN博客
b. huggingface连接问题2
HTTPSConnectionPool(host=‘huggingface.co‘, port=443)
诊断:常见的Transformer使用报错问题,原因是网络的无法稳定访问下载Tokenizer,用a中的方案三也可以解决
c. cuda问题
AssertionError:Torch not compiled with CUDA enabled
解决方案:错误Torch not compiled with CUDA enabled解决方法附CUDA安装教程及Pytorch安装教程-CSDN博客
如果是使用CPU:加上 DEVICE = “cpu”
from groundingdino.util.inference import load_model, load_image, predict, annotate
import cv2
import os
model = load_model("E:/Jupyter_Norebook_dir/GroundingDINO-main/GroundingDINO-main/groundingdino/config/GroundingDINO_SwinT_OGC.py",
"E:/Jupyter_Norebook_dir/GroundingDINO-main/GroundingDINO-main/groundingdino_swint_ogc.pth")
IMAGE_PATH = "E:/Jupyter_Norebook_dir/GroundingDINO-main/GroundingDINO-main/.asset/cat_dog.jpeg"
TEXT_PROMPT = "chair . person . dog ."
BOX_TRESHOLD = 0.35
TEXT_TRESHOLD = 0.25
DEVICE = "cpu"
os.environ['TRANSFORMERS_OFFLINE']="1"
image_source, image = load_image(IMAGE_PATH)
boxes, logits, phrases = predict(
model=model,
image=image,
caption=TEXT_PROMPT,
box_threshold=BOX_TRESHOLD,
text_threshold=TEXT_TRESHOLD,
device=DEVICE
)
annotated_frame = annotate(image_source=image_source, boxes=boxes, logits=logits, phrases=phrases)
cv2.imwrite("annotated_image.jpg", annotated_frame)
解决这些问题后运行成功
3. 测试结果
3.1 测试案例1:多目标情况
输入图片:多个目标且是较为常见的目标

结果一:TEXT_PROMPT = “lion . horse . pig .”

可以看到当TEXT_PROMPT少且不准确时,结果一般且目标框不全
结果二:TEXT_PROMPT = “lion . horse . rhinoceros . deer . bird . elephant . elephant . fox . cheetah . giraffe . mountain . “

可以看到当TEXT_PROMPT多且准确时,结果有较小提升,但仍旧有一定错误
结果三:TEXT_PROMPT = “lion . horse . rhinoceros . deer . bird . elephant . elephant . fox . cheetah . giraffe . pig .cat . dog . cup . person . tiger”

可以看到当TEXT_PROMPT多且不准确时,结果与多且准确相同
综上,给我们的启示是:TEXT_PROMPT要尽量多且全面
3.2 测试案例2:少目标情况
输入图片:2-3个目标且是较为常见的目标

结果一:TEXT_PROMPT = “lion . horse . rhinoceros . deer . bird . elephant . mountain . fox . cheetah . giraffe . pig .cat . dog . cup . person . girl . child”

可以看到,除了熊识别失误以外,没有把小女孩识别出来,这可能与TEXT_PROMPT中有混淆概念“person . girl . child”有关
结果二:TEXT_PROMPT = “lion . horse . rhinoceros . deer . bird . elephant . mountain . fox . cheetah . giraffe . pig .cat . dog . cup . person . “

可以看到,去除混淆概念后,很好地识别出了小女孩;
在“person . girl . child”中仅留下“girl ”或“child”结果也是一样的

综上,给我们的启示是:TEXT_PROMPT要在尽量多的同时,避免混淆概念
3.3 测试案例3:少见目标情况
输入图片:极为少见的目标

TEXT_PROMPT = “lion . horse . rhinoceros . deer . bird . elephant . mountain . fox . cheetah . giraffe . pig .cat . dog . cup . monkey . frog .”

可以看到结果不佳